Природа генетического кода
Проблема синтеза белка тесно связана с понятием генетического кода. Генетическая информация, закодированная в первичной структуре ДНК, еще в ядре переводится в нуклеотидную последовательность мРНК. Вопрос о том, каким образом эта информация передается на белковую молекулу, долго не был ясен. Первые указания на существование прямой линейной зависимости между структурой гена и его продуктом – белком можно найти у Ч. Яновского. В серии изящных опытов с применением методов генетического картирования и секвенирования он показал, что порядок изменений в структуре мутантного гена триптофансинтазы у Е. coli точно соответствует порядку изменений в аминокислотной последовательности молекулы белка-фермента.
Эукариотические клетки обладают особым механизмом точного и эффективного перевода последовательности мРНК в соответствующую последовательность аминокислот синтезируемого белка. Сами молекулы мРНК не имеют сродства к аминокислотам, и было высказано предположение о том, что для перевода нуклеотидной последовательности мРНК на аминокислотную последовательность белков необходим некий посредник, названный адаптором (см. ранее). Молекула адаптора должна быть наделена способностью узнавать нуклеотидную последовательность специфической мРНК и соответствующую аминокислоту. Клетка, имеющая подобную адапторную молекулу, может встраивать каждую аминокислоту в подходящее место полипептидной цепи в строгом соответствии с нуклео-тидной последовательностью мРНК. Остается, таким образом, незыблемым положение, что сами по себе функциональные группы аминокислот не способны вступать в контакт с матрицей и информационной мРНК.
Было показано, что в нуклеотидной последовательности мРНК имеются кодовые «слова» для каждой аминокислоты – генетический код. Вероятнее всего, он заключается в определенной последовательности расположения нуклеотидов в молекуле ДНК. Вопросы о том, какие нуклеотиды ответственны за включение определенной аминокислоты в белковую молекулу и какое количество нуклеотидов определяет это включение, оставались нерешенными до 1961 г. Теоретический разбор показал, что код не может состоять из одного нуклеотида, поскольку в этом случае только 4 аминокислоты могут кодироваться. Однако код не может быть и дуплетным, т.е. комбинация двух нуклеотидов из четырехбуквенного «алфавита» не может охватить всех аминокислот, так как подобных комбинаций теоретически возможно только 16 (42 = 16), а в состав белка входит 20 аминокислот. Для кодирования всех аминокислот белковой молекулы был бы достаточным триплетный код, когда число возможных комбинаций составит 64 (43 = 64).
Из приведенных данных М. Ниренберга становится очевидным, что поли-У, т.е. РНК, гипотетически содержащая остатки только одного уридилового мононуклеотида, способствует синтезу белка, построенного из остатков одной аминокислоты – фенилаланина. На этом основании был сделан вывод, что кодоном для включения фенилаланина в белковую молекулу может служить триплет, состоящий из трех уридиловых нуклеотидов – УУУ. Вскоре было показано, что синтетическая матричная поли-цитидиловая кислота (поли-Ц) кодирует образование полипролина, а матричная полиадениловая кислота (поли-А) – полилизина; соответствующие триплеты ЦЦЦ и ААА действительно оказались триплетами (кодонами) для кодирования пролина и лизина.
В выяснении полного генетического кодового «словаря» выдающуюся роль сыграли разработанные Г. Хорана подходы к синтезу полирибо-нуклеотидов (искусственных мРНК) с определенными повторяющимися триплетными последовательностями (кополимеры). Их потом использовали в качестве матрицы в белоксинтезирующей системе. Образованные при этом полипептиды содержали равные количества аминокислот в полном соответствии с матрицей кополимера.
Вскоре в лабораториях М. Ниренберга, С. Очоа и Г. Хорана, пользуясь этими искусственно синтезированными мРНК, были представлены доказательства не только состава, но и последовательности триплетов всех кодонов, ответственных за включение каждой из 20 аминокислот в белковую молекулу. Приводим полный кодовый «словарь», т.е. все 64 кодона:
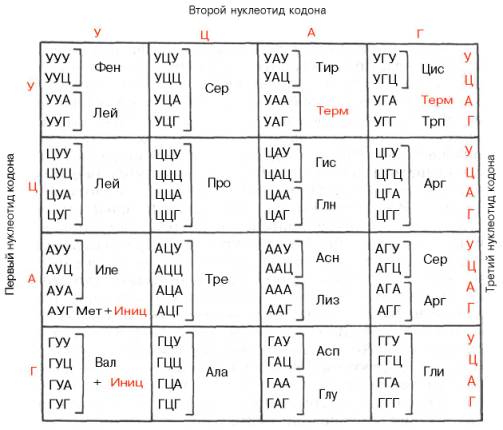
Генетический код для аминокислот является вырожденным. Это означает, что значительное большинство аминокислот кодируется несколькими кодонами. За исключением метионина и триптофана, по существу все остальные аминокислоты имеют более одного специфического кодона. Узнавание кодона мРНК антикодоном тРНК основано не только на спаривании оснований, когда каждое основание кодона образует пару оснований с комплементарным азотистым основанием антикодона. В этом случае каждый антикодон, соответственно каждая молекула тРНК, может в принципе узнавать только один кодон мРНК. Имеются данные о том, что некоторые тРНК могут узнавать более одного кодона. В частности, показано, что аланиновая тРНК, выделенная из дрожжей, узнает 3 кодона: ГЦУ, ГЦЦ и ГЦА. Как видно, различия касаются только природы 3-го нуклеотида. В связи с этим была выдвинута гипотеза «качаний», предполагающая, что на спаривание 3-го основания, очевидно, накладываются менее строгие ограничения и что имеется неполное, неоднозначное соответствие этого нуклеотида, являющееся, вероятнее всего, одной из причин вырожденности генетического кода. Вырожденность кода оказывается неодинаковой для разных аминокислот. Так, если для серина, аргинина и лейцина имеется по 6 кодовых «слов», то ряд других аминокислот, в частности глутаминовая кислота, гистидин и тирозин, имеют по 2 кодона, а триптофан – только 1. Вполне допустимо поэтому предположение, что последовательность первых двух нуклеотидов определяет в основном специфичность каждого кодона, в то время как 3-й нуклеотид, очевидно, менее существен. В последнее время появились сторонники возможности существования гипотезы два из трех, означающей, что код белкового синтеза, возможно, является квази- или псевдодуплетным.
Оказалось, что вырожденность генетического кода имеет несомненный биологический смысл, обеспечивая организму ряд преимуществ. В частности, она способствует «совершенствованию» генома, так как в процессе точечной мутации, вызванной химическими или физическими факторами, возможны различные аминокислотные замены, наиболее ценные из которых отбираются в процессе эволюции.
Другой отличительной особенностью генетического кода является его непрерывность, отсутствие «знаков препинания», т.е. сигналов, указывающих на конец одного кодона и начало другого. Другими словами, код является линейным, однонаправленным и непрерывающимся: АЦГУЦГАЦЦ. Это свойство генетического кода обеспечивает синтез точной и в высшей степени упорядоченной последовательности аминокислотных остатков в молекуле белка. В противном случае последовательность нуклеотидов в кодонах будет нарушена и приведет к синтезу «бессмысленной» полипептидной цепи с измененной структурой и непредсказуемой функцией. Следует указать еще на одну весьма существенную особенность кода – его универсальность для всех живых организмов от Е. coli до человека. Код не подвергся существенным изменениям за миллионы лет эволюции.
Среди 64 мыслимых кодонов 61 имеет смысл, т.е. кодирует определенную аминокислоту. В то же время три из них, а именно УАГ, УАА, УГА, оказываются «бессмысленными»; они были названы нонсенс-кодо-нами, так как не кодируют ни одной из 20 аминокислот. Однако эти кодоны не лишены смысла, поскольку по крайней мере два из них выполняют важную функцию сигналов терминации в синтезе полипептида в рибосомах (функцию окончания, терминации синтеза).
При исследовании генетического кода в опытах in vivo также были получены доказательства универсальности кода, однако в последние годы выявлены некоторые особенности его в митохондриях животных, включая клетки человека. Генетический код цитоплазмы отличается от такового митохондрий 4 кодонами. Два кодона: АУГ, который обычно является инициаторным кодоном, кодирует также метионин в цепи, и УГА, являющийся нонсенс-кодоном, кодирует в митохондриях триптофан. Кодоны АГА и АГГ являются для митохондрий скорее терминирующими, а не кодирующими аргинин. В результате для считывания генетического кода митохондрий требуется меньше разных тРНК, в то время как цито-плазматическая система трансляции обладает полным набором тРНК.